[Update 5 de Junho] este tutorial foi adaptado e publicado na documentação oficial da Magalu Cloud!
Infraestrutura como Código
Infraestrutura como código (IaC) é o nome dado a prática de utilizar arquivos de configuração em repositórios de código para descrever a infraestrutura de recursos computacionais (servidores, redes, armazenamento, bancos de dados, acessos, DNS, etc).
É comum em empresas que consomem serviços de nuvem o uso da ferramenta Terraform para organizar configurações de infraestrutura e para automatizar os provisionamentos dela.
O surgimento da Lu-vem
Por aqui, temos uma nova nuvem em construção, a MagaluCloud, que é também a empresa onde eu atualmente trabalho. É um projeto ambicioso, uma nova cloud pública, com duas regiões no Brasil, com suporte em português, preços em Reais e com muita gente boa no time.
Um dos primeiros produtos oferecidos por esta nuvem é o de Object Storage, que é uma solução escalável para armazenamento de dados compatível com o padrão AWS S3 da Amazon.
OpenTofu + S3 + Magalu Cloud
Abaixo segue um pequeno tutorial de como utilizar o OpenTofu, que é uma alternativa livre ao Terraform, para a criação e gerenciamento de recursos de Object Storage.
Pérrequisitos
Este tutorial assume que você tenha:
- uma conta da Magalu com acesso ao console da nuvem
- um sistema Linux (exemplo: Ubuntu)
- a ferramenta OpenTofu numa versão igual ou superior a
v1.7.1
Projeto e Módulo Raíz
Vamos começar criando uma pasta para nosso projeto e um módulo de configuração raíz:
mkdir tutorial-tofu
cd tutorial-tofu
echo "terraform {}" > main.tf
tofu validate
Apesar de válida, esta configuração raíz está vazia. Módulos de Terraform utilizam plugins chamados de Providers que são extensões instaláveis que permitem o uso de diferentes produtos de diferentes nuvens.
Para este tutorial, vamos utilizar o provider hashicorp/aws (licença MPL v2.0), que habilita o uso de fornecedores de Object Storage compatíveis com o padrão S3. Para isto vamos aumentar nosso main.tf para ficar assim:
# main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.50.0"
}
}
}
provider "aws" {
# Configuration options
}
E utilizar o comando abaixo para instalar este plugin:
tofu init
Voltaremos na linha comentada acima após criarmos um "profile aws" com credenciais de acesso no passo a seguir.
Configuração das credenciais
Por ser compatível com S3, o Object Storage da nuvem da Magalu funciona também com autenticação por API Key, no console você pode criar uma chave destas indo em Início > Object Storage > API Key, botão "Criar API Key"
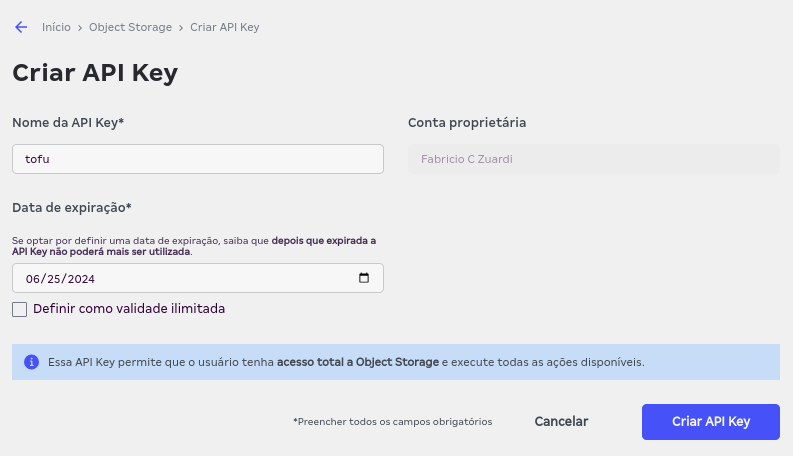
Esta chave possui duas informações importantes para serem configuradas na sua máquina: ID e Secret. Para este tutorial, vamos declarar estas variáveis num arquivo de configuração de perfis da aws, que deve estar localizado no caminho ~/.aws/credentials, vamos dar o nome deste perfil de tutorial-tofu, substitua os textos em caixa alta COLE_AQUI_O... no exemplo abaixo pelo conteúdo do ID e do SECRET da chave recém criada:
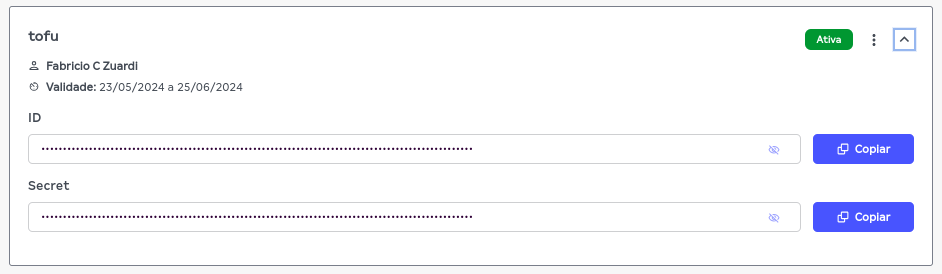
mkdir -p ~/.aws
cat << EOF >> ~/.aws/credentials
[tutorial-tofu]
aws_access_key_id = COLE_AQUI_O_ID
aws_secret_access_key = COLE_AQUI_O_SECRET
EOF
O padrão destes perfis de aws é utilizar a nuvem da Amazon. Para funcionar com a nuvem da Magalu, é preciso mudar os campos endpoint_url e region, neste exemplo vou utilizar a região "Brasil - Nordeste 1", a br-ne1:
cat << EOF >> ~/.aws/config
[profile tutorial-tofu]
endpoint_url = https://br-ne1.magaluobjects.com/
region = br-ne1
EOF
Se tudo deu certo, podemos voltar ao módulo raíz do nosso projeto e incluir este nome de perfil como o campo profile do bloco que configura o provider aws:
provider "aws" {
profile = "tutorial-tofu"
skip_region_validation = true
skip_requesting_account_id = true
skip_credentials_validation = true
}
(este alinhamento dos sinais de igual é culpa do tofu fmt, não me xinguem)
Estes outros três atributos (skip isto, skip aquilo, skip aquilo outro) serão necessários também para o nosso caso, detalhes sobre cada um deles podem ser consultados na documentação do plugin.
Primeiro Bucket
Finalmente, podemos criar o primeiro recurso de nossa infraestrutura: um bucket para armazenarmos objetos dentro, vamos criar um novo módulo de configuração, um arquivo: resources.tf
# resources.tf
resource "aws_s3_bucket" "first_bucket" {
bucket_prefix = "tutorial-bucket"
}
Nota: Utilizei o campo
bucket_prefixao invés do campobucketpara nomear nosso primeiro contêiner pois, assim como na AWS, os nomes de buckets na Magalu Cloud também são globais e devem ser únicos, portanto ao invés de inventar um nome único, forneci só um prefixo e deixei para o provider a tarefa de preencher o resto do nome com um numero aleatório único.
Neste ponto, já podemos utilizar o comando tofu plan para planejar o provisionamento:
tofu plan
Este comando lista as mudanças nos recursos que serão necessárias para refletir o estado final descrito nas configurações declarativas do projeto. No nosso caso, ele listará a criação de um bucket: "# aws_s3_bucket.first_bucket will be created"
E posteriormente aplicar este plano:
tofu apply -compact-warnings
Ele vai exibir o plano novamente e pedir para você digitar yes.
Se tudo der certo este processo deve terminar com uma mensagem parecida com esta:
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
O estado deste novo recurso pode ser consultado com os comandos tofu state list e tofu state show
A criação deste bucket pode ser verificada também pela listagem do console via navegador:
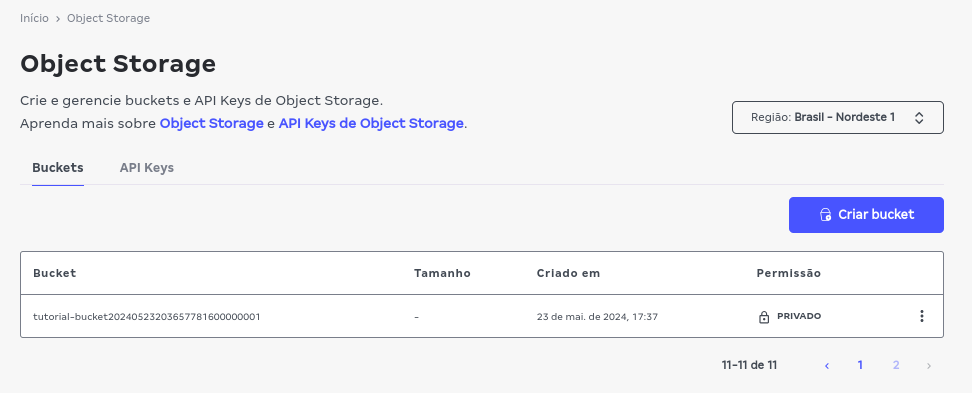
Lembre-se de mudar a região para "Brasil -Nordeste 1" caso seu console esteja em outra região:
Mais recursos: objetos
Agora que temos um resource do tipo aws_s3_bucket criado, vamos utilizar um resource do tipo aws_s3_object para adicionar dois arquivos dentro deste bucket:
# resources.tf
resource "aws_s3_bucket" "first_bucket" {
bucket_prefix = "tutorial-bucket"
}
resource "aws_s3_object" "first_bucket_objects" {
for_each = tomap({
file1 = "./main.tf"
file2 = "./resources.tf"
})
bucket = aws_s3_bucket.first_bucket.id
key = each.value
source = each.value
}
Um tofu plan vai nos dizer:
Plan: 2 to add, 0 to change, 0 to destroy.
E o posterior tofu apply:
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
Pronto, os dois arquivos estão na nuvem. Um tofu state list deve mostrar agora 3 resources:
$ tofu state list
aws_s3_bucket.first_bucket
aws_s3_object.first_bucket_objects["file1"]
aws_s3_object.first_bucket_objects["file2"]
State do segundo object:
$ tofu state show 'aws_s3_object.first_bucket_objects["file2"]'
# aws_s3_object.first_bucket_objects["file2"]:
resource "aws_s3_object" "first_bucket_objects" {
arn = "arn::s3:::tutorial-bucket20240523203657781600000001/resources.tf"
bucket = "tutorial-bucket20240523203657781600000001"
bucket_key_enabled = false
content_type = "application/octet-stream"
etag = "01d689431df57be26625e8fb41ac04d2"
force_destroy = false
id = "./resources.tf"
key = "./resources.tf"
source = "./resources.tf"
storage_class = "STANDARD"
tags_all = {}
}
Desprovisionando Tudo
Tão importante como saber criar coisas na nuvem, é saber como limpar tudo para no fim do mês não receber uma surpresa na conta do cartão de crédito. Este tutorial não estaria completo se não ensinasse como apagar estes recursos todos, por mais baratos que sejam:
tofu destroy
Destroy complete! Resources: 3 destroyed.
Configuração e Estado
Como visto acima, o comando tofu state tem funções para mostrar o que o sistema sabe sobre a instalação real da infraestrutura descrita no código dos módulos de configuração. Ter a declaração em arquivos de como as máquinas deveriam estar e saber como elas de fato estão são duas coisas diferentes, esta segunda parte é o "state", o estado da instalação.
Na minha config eu declarei que a instalação tinha que ter um bucket com um certo prefixo no nome e dois objetos dentro, com o caminho dos arquivos locais para cada objeto.
O estado vai ter bem mais informação que isto, como por exemplo o nome completo que o bucket recebeu, as etags de cada objeto e vários outros detalhes.
Um ls no diretório do projeto vai mostrar a existência de dois arquivos gerados que descrevem o estado atual e o estado anterior da minha instalação:
terraform.tfstate terraform.tfstate.backup
Um less no arquivo atual, depois do destroy, vai mostrar que o estado atual não possui nenhum recurso por exemplo:
$ less -F terraform.tfstate
{
"version": 4,
"terraform_version": "1.7.1",
"serial": 7,
"lineage": "51390cb1-af8e-d82b-99d6-1bb5da876657",
"outputs": {},
"resources": [],
"check_results": null
}
Compartilhando o estado com o time
Num cenário onde várias pessoas vão trabalhar na mesma infra, ter as configs e este estado apenas local na máquina de quem executou o plano por último não é o ideal. Ao mesmo tempo, por conter informações sensíveis, não é recomendado colocar os arquivos tfstate.* num repositório git, especialmente se este repositório for público.
Uma possível saída para coordenar este trabalho em grupo e compartilhar de maneira privada o estado da instalação, é usar a funcionalidade de estado remoto, que suporta várias opções de onde armazenar este estado, implementados por diferentes backends.
Vamos então finalizar este tutorial com um exemplo de como configurar o OpenTofu para armazenar o estado remotamente num bucket de S3 da Magalu Clloud, utilizando o backend "s3".
Primeiro, vamos criar um bucket novo só para isto, num arquivo novo state-bucket.ft:
# state-bucket.tf
resource "aws_s3_bucket" "state_bucket" {
bucket_prefix = "tutorial-state-bucket"
}
tofu apply
Agora vamos exibir na tela o nome do bucket gerado para copiar e usar na config do backend depois:
tofu state show aws_s3_bucket.state_bucket
E finalmente, de volta no main.tf adicionamos este bloco backend "s3" ao bloco terraform
# main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.50.0"
}
}
backend "s3" {
bucket = "NOME_DO_SEU_BUCKET_DE_STATE_AQUI"
key = "the_state"
region = "br-ne1"
profile = "tutorial-tofu"
skip_region_validation = true
skip_requesting_account_id = true
skip_credentials_validation = true
skip_s3_checksum = true
}
}
provider "aws" {
profile = "tutorial-tofu"
skip_region_validation = true
skip_requesting_account_id = true
skip_credentials_validation = true
}
E para instalar o backend:
tofu init
Nota num cenário mais real talvez o bucket de state não viveria no mesmo projeto, ou teria alguma prevenção tipo
lifecycle { prevent_destroy = true }, ou seria criado manualmente. Eu criei junto aqui apenas para facilitar o tutorial.
Considerações finais
IaC e OpenTofu podem ajudar na organização e manutenção de sistemas na nuvem.
Esta introdução, apesar de ser na cloud da Magalu, utilizou um provider genérico de S3, optei por fazer assim para demonstrar compatibilidade, porém existe um provider de Terraform da MagaluCloud, que inclui outros recursos, como máquinas virtuais por exemplo, documentação aqui.
O tema é vasto, e eu não sou nenhum expert no assunto, escrevi este texto por estar também conhecendo este mundo. Se houver demanda posso continuar esta série, Terragrunt por exemplo é uma ferramenta que eu já ouvi falar mas nunca testei pessoalmente.
Remixe
Se achou parte deste artigo útil, por favor replique, este texto está licenciado sob a Creative Commons Atribuição 4.0.
Foto do cabeçalho:
Homemade Tofu - Cocoro Cafe, QVM AUD10 set by Alpha, on Flickr
se você gostou deste post e quiser receber novas atualizações deste blog por email, clique aqui